
$35
Problem Set 2 Solution
This assignment introduces you to some theoretical results that address which neural networks can represent what. It walks you through proving some simplified versions of more general results. In particular, this assignment focuses on piecewise linear neural networks, which are the most common type at the moment. The general strategy will be to construct a neural network that has the desired properties by choosing appropriate sets of weights.
- Convolution Basics
The convolution layer inside of a CNN is intrinsically an affine transformation: A vector is received as input and is multiplied with a matrix to produce an output (to which a bias vector is usually added before passing the result through a nonlinearity). This operation can be represented as y = Ax, in which A describes the affine transformation.
- [2 points] We will first revisit the convolution layer as discussed in the class. Consider a convolution layer with a 3x3 kernel W , operated on a single input channel X, represented as:

Now let us work out a stride-2 convolution layer, with zero-padding size of 1. Consider ‘flattening’ the input tensor X in row-major order as:
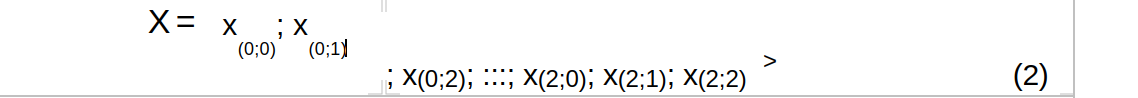
Write down the convolution as a matrix operation A that: Y = AX. Output Y is also flattened in row-major order.
- [2 points] Recall that transposed convolution can help us upsample the feature size spatially. Consider a transposed convolution layer with a 2x2 kernel W operated on a single input channel X, represented as:
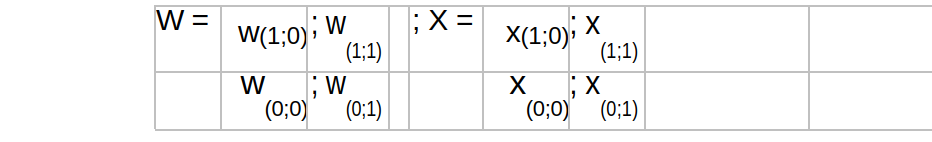
We ‘flattened’ the input tensor in row-major order as X = [x(0;0); x(0;1); x(1;0); x(1;1)].
Write down the affine transformation A corresponding to a transposed convolution layer with kernel W , stride 2, no padding. Output Y is also flattened in row-major order.
- Logic
- [4 points] Implement AND and OR for pairs of binary inputs using a single linear threshold
neuron with weights w 2 R2, bias b 2 R, and x 2 f0; 1g2:

Show that “,” can NOT be represented using a linear model with the same form as (4).
[Hint: To see why, plot the examples from above in a plane and think about drawing a linear boundary that separates them.]
- Depth - Composing Linear Pieces [Extra Credit for 4803; Regular Credit for 7643]
An
interesting property of networks with piecewise linear activations
like the ReLU is that on the whole they compute piecewise linear
functions. For instance, each layer h(i) below computes a linear
function of the previous layer, h(i 1), and the resulting function is
piecewise-linear in x:
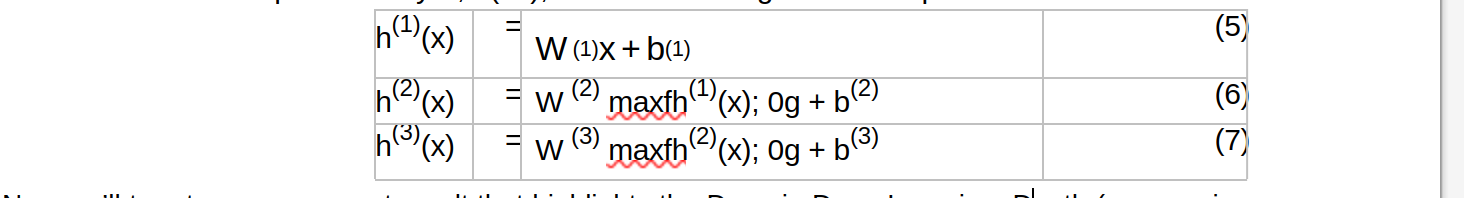
Now we’ll turn to a more recent result that highlights the Deep in Deep Learning. Depth (compos-ing more functions) results in a favorable combinatorial explosion in the “number of things that a neural net can represent”. For example, to classify a cat it seems useful to first find parts of a cat: eyes, ears, tail, fur, etc. The function which computes a probability of cat presence should be a function of these components because this allows everything you learn about eyes to generalize to all instances of eyes instead of just a single instance. Below you will detail one formalizable sense of this combinatorial explosion for a particular class of piecewise linear networks.

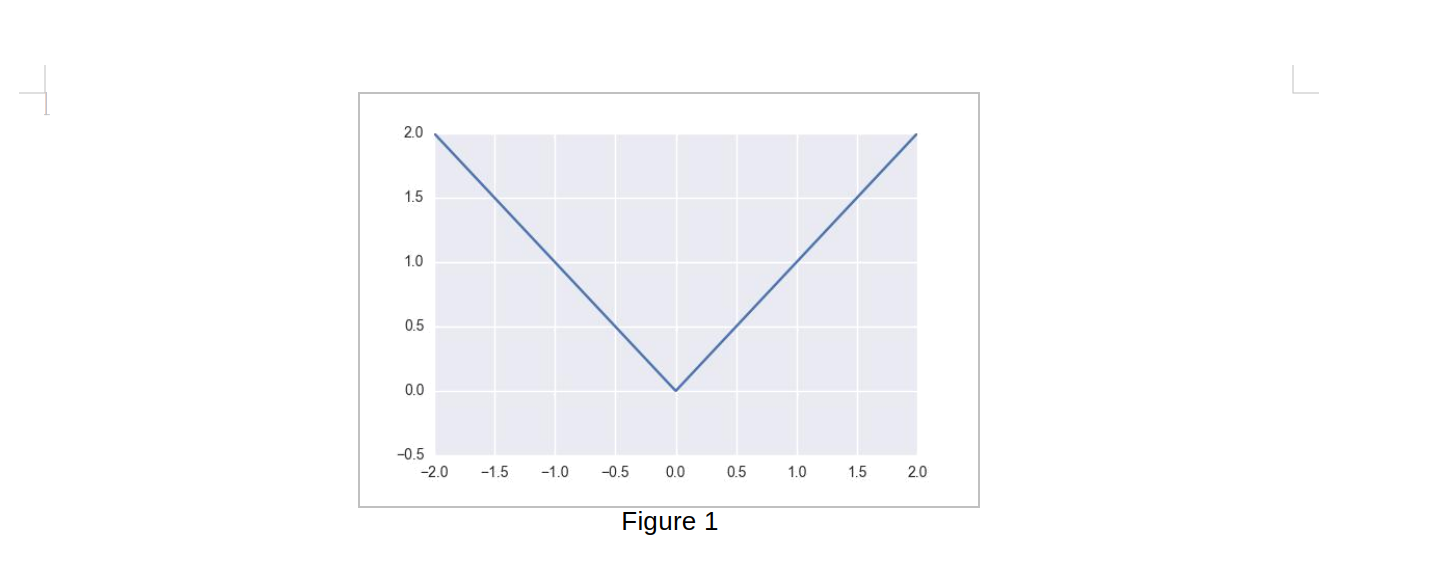
Figure 1
Consider y = (x) = jxj for scalar x 2 X R and y 2 Y R (Fig. 1). It has one linear re-gion on x < 0 and another on x > 0 and the activation identifies these regions, mapping both of them to y > 0. More precisely, for each linear region of the input, ( ) is a bijection. There is a mapping to and from the output space and the corresponding input space. However, given an output y, it’s impossible to tell which linear region of the input it came from, thus ( ) identifies (maps on top of each other) the two linear regions of its input. This is the crucial definition because when a function identifies multiple regions of its domain that means any subsequent computation applies to all of those regions. When these regions come from an input space like the space of im-ages, functions which identify many regions where different images might fall (e.g., slightly different images of a cat) automatically transfer what they learn about a particular cat to cats in the other regions.
More formally, we will say that ( ) identifies a set of M disjoint input regions R = fR1; : : : ; RM g (e.g., R = f( 1; 0); (0; 1)g) with Ri X onto one output region O Y (e.g., (0; 1)) if for all Ri 2 R there is a bijection from Ri to O. 1
-
[4
points] Start by applying the above notion of identified regions to
linear regions of one layer of a particular neural net that uses
absolute value functions as activations. Let x 2 Rd,
y 2 Rd
2,
and pick weights W (1)
2 Rd
d
and bias b(1)
2 Rd
as follow
- [4 points] Next consider what happens when two of these functions are composed. Suppose g identifies ng regions of (0; 1)d onto (0; 1)d and f identifies nf regions of (0; 1)d onto (0; 1)d. How many regions of its input does f g( ) identify onto (0; 1)d?
- [6
points] Finally consider a series of L layers identical to the one
in question 4.1.

Let x 2 (0; 1)d and f(x) = hL. Note that each hi is implicitly a function of x. Show that f(x) identifies 2Ld regions of its input.
4 Conclusion to Theory Part
Now compare the number of identified regions for an L layer net to that of an L 1 layer net. The
L layer net can separate its input space into 2d more linear regions than the L 1 layer net. On the other hand, the number of parameters and the amount of computation time grows linearly in the number of layers. In this very particular sense (which doesn’t always align well with practice) deeper is better.
To summarize this problem set, you’ve shown a number of results about the representation power of different neural net architectures. First, neural nets (even single neurons) can represent logical operations. Second, neural nets we use today compute piecewise linear functions of their input. Third, the representation power of neural nets increases exponentially with the number of layers.
The point of the exercise was to convey intuition that removes some of the magic from neural nets representations. Specifically, neural nets can decompose problems logically, and “simple” piecewise linear functions can be surprisingly powerful.
- Paper Review
The second of our paper reviews for this course comes from some interesting work at Facebook AI Research (FAIR) last year exploring the limits of weakly supervised learning and improving upon their results on the ImageNet dataset by appending data from Instagram using hashtags as ground truth labels. The paper can be viewed here.
Guidelines: Please restrict your answers to no more than 350 words combined. The evaluation rubric for this section is as follows :
- [2 points] The paper shows that training with very weak (noisy) labels still leads to robust learning of features that generalize well. Why is deep learning so robust to noise? Provide some conjectures, relating it to what you know about machine/deep learning and optimization.
- [2 points] Another finding is that learning features using similar label spaces (i.e. on cate-gories that overlap with what you are hoping to generalize to) is more successful than learning features on dissimilar label spaces. Why might that be the case?
Coding: Gradients With Respect to Input [65 points]
The coding part of this assignment will have you implement different ideas which all rely on gradients of some neural net output with respect to the input image. To get started go to
https://www.cc.gatech.edu/classes/AY2020/cs7643_spring/Z3o9P26CwTPZZMDXyWYDj3/hw2/.